
この記事では、Ollamaを使用して大規模言語モデル(LLM)を一般的なPCに導入し、 自分だけのAIアシスタントを構築する方法について紹介します。
Ollamaとは、AI(LLM)モデルのダウンロードと実行ができるLLM導入ツールです。
Ollamaを利用することで、いとも簡単に手持ちPCで動作するAIを導入できることを知ってもらい、 AI技術について身近に感じて頂けたらと思います。
AIとチャットをするためのインタフェース(WebUI)の作成や、宅内ネットワーク内で家族もAIが利用できるようになる設定についても紹介します。
目的とする用途に応じて本記事の内容を読んで頂ければ幸いです。
目次
- AI(LLM)を実行するのに必要なメモリ容量について
- Ollamaのインストール
- LLMモデルファイルをダウンロードしてAIと会話をしてみる
- AIチャットインタフェース(WebUI)の作成
- 宅内ネットワーク(LAN)内で家族もAIを利用できるようにする方法
- おわりに
- 余談その1
- 余談その2(2025年1月13日追記)
- 参考文献
AI(LLM)を実行するのに必要なメモリ容量について
この記事ではOllamaによるAI(LLM)の実行方法を紹介するわけですが、そもそもな話として 読者お使いのPCがLLMの実行要件を満たしている必要があります。
LLMの実行要件として、一番問題になるのがメモリ(RAM)サイズと思われます。
メモリ占有量は個々のLLMで異なりますが、大半のLLMが最低でも8GBのRAMを必要とします。 (ちなみにLLMを実行するための推奨メモリサイズは16GB以上です。)
お使いのPCが対象LLMのメモリサイズ要件を満たしてない場合、エラーが発生して起動できません ので予めご了承ください。
Ollamaのインストール
早速、Ollamaをインストールしましょう。
この記事では、WindowsとLinuxでのインストール方法について紹介します。
WindowsにOllamaをインストールする
公式サイトのWindowsインストールページにアクセスして次の画面を表示し、「Download for Windows (Preview)」ボタンをクリックしてインストーラーをダウンロードします。
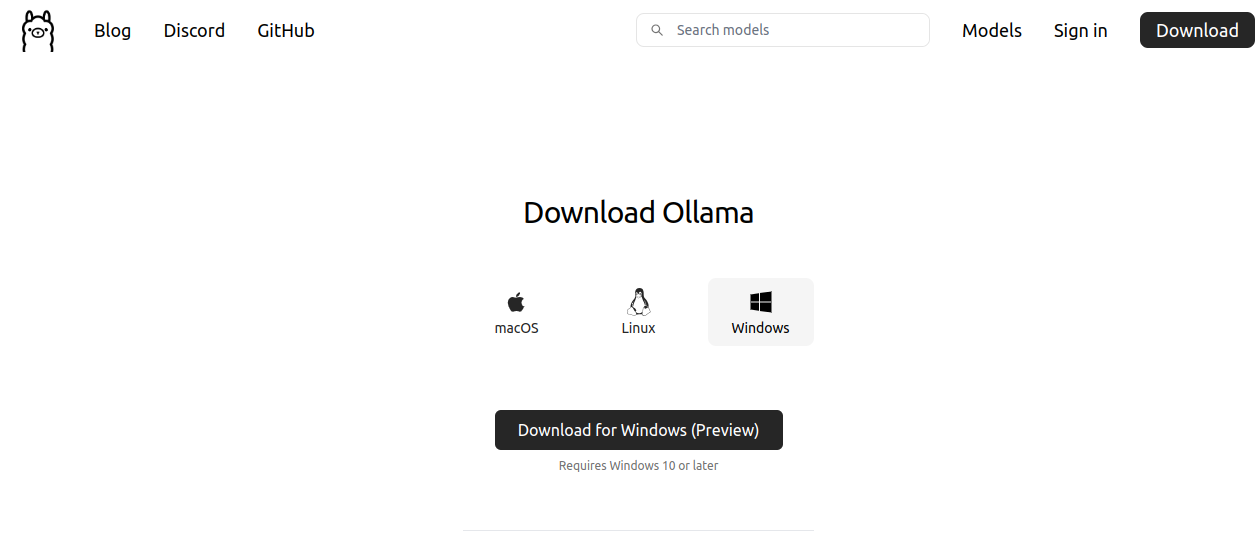
インストーラを起動すると次の画面が表示されますので、「install」をクリックします。
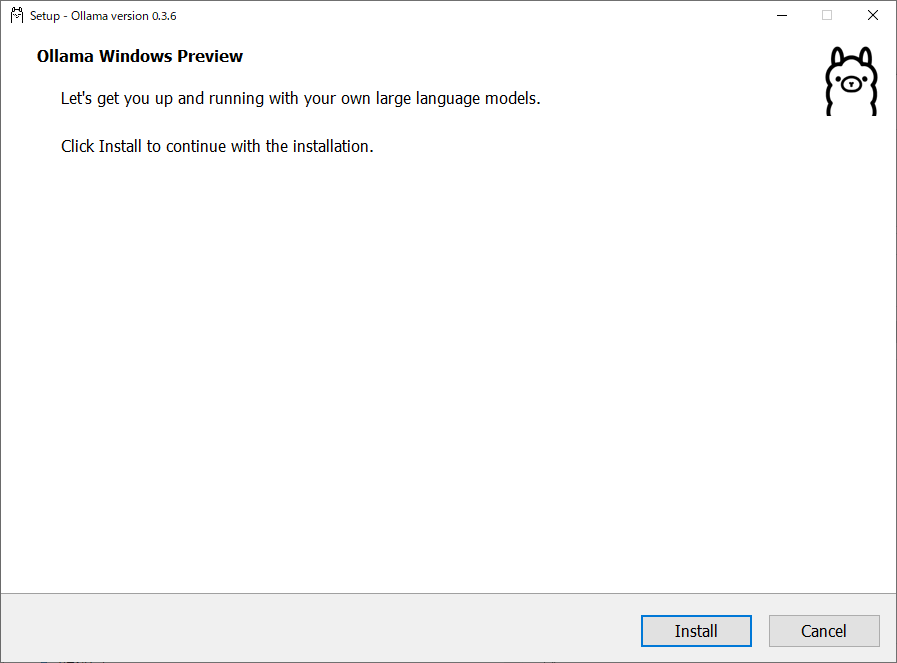
問題なければここでOllamaのインストールは完了します。Windowsの場合、メインウィンドウ右下のインジケーターにラマのアイコン が表示されますので、そこからログの確認や起動・停止ができます。
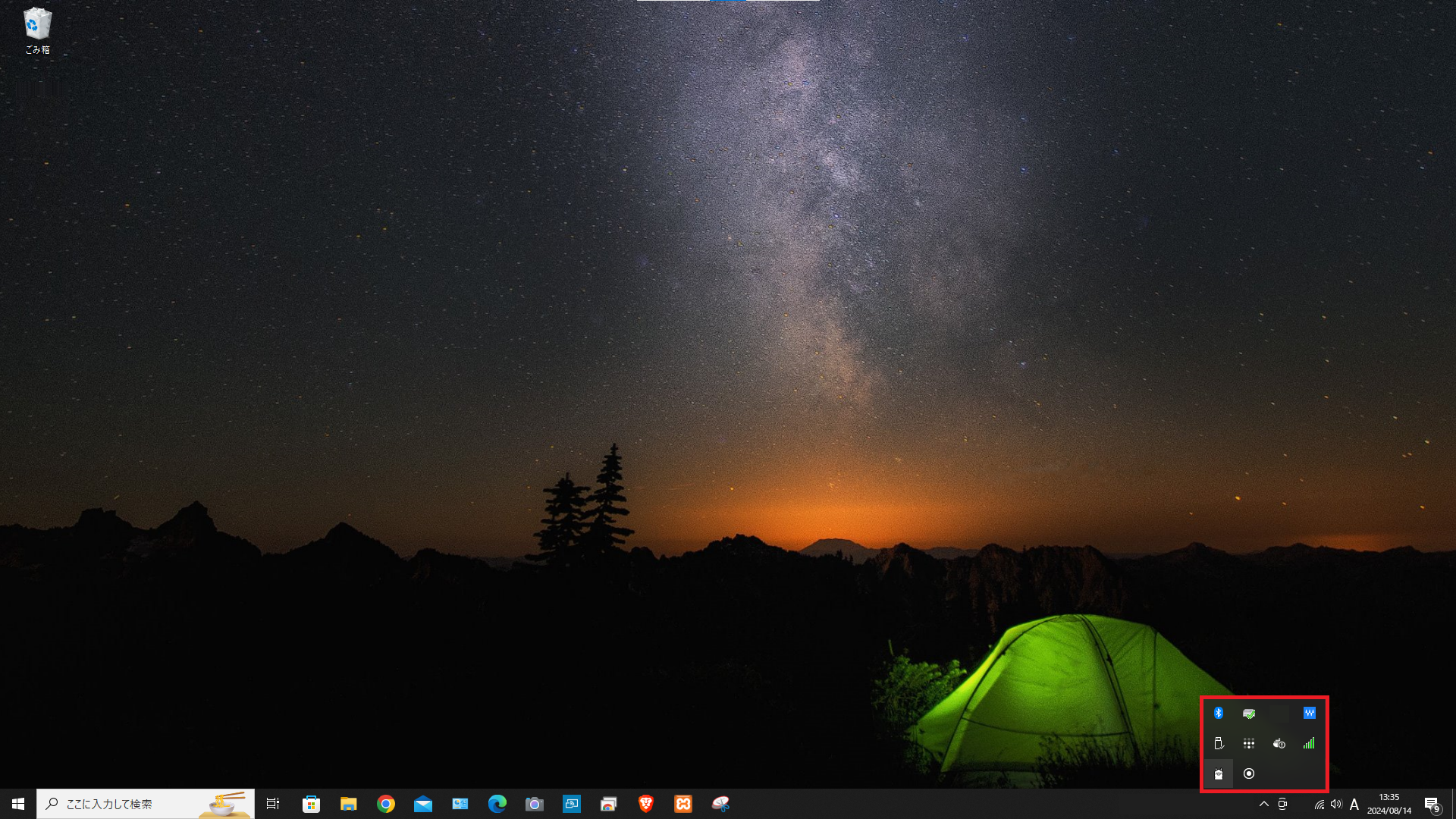
また、検索欄(上画像の左下)に「cmd」と打ち込んでコマンドプロンプトを起動し、コンソールにollamaと入力してEnterを押すと コマンドのヘルプ画面が表示されます。
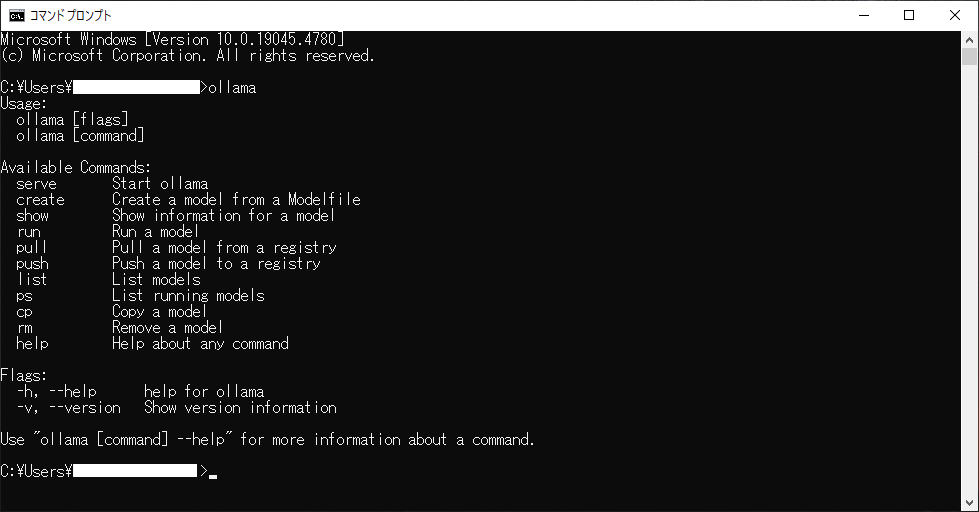
後は次節で紹介するAI(LLM)モデルのダウンロードを実施することでAIと会話ができます。
LinuxにOllamaをインストールする
公式サイトのLinuxインストールページにアクセスして次の画面を表示します。
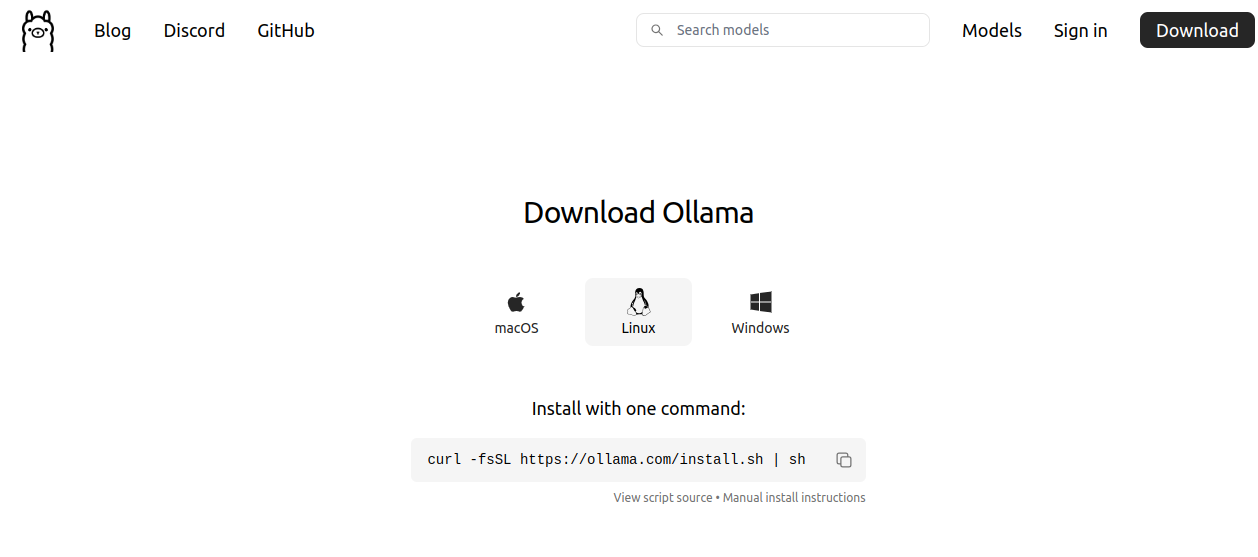
すると、ollamaのインストールスクリプトをダウンロードして実行する以下のコードが掲載されていますので、PCのコンソール上でコピペしてEnterを押します。
kamo@kamo:~$ curl -fsSL https://ollama.com/install.sh | sh
>>> Downloading ollama...
######################################################################## 100.0%######################################################################### 100.0%
>>> Installing ollama to /usr/local/bin...
[sudo] password for kamo:
>>> Creating ollama user...
>>> Adding ollama user to render group...
>>> Adding ollama user to video group...
>>> Adding current user to ollama group...
>>> Creating ollama systemd service...
>>> Enabling and starting ollama service...
Created symlink /etc/systemd/system/default.target.wants/ollama.service → /etc/systemd/system/ollama.service.
>>> The Ollama API is now available at 127.0.0.1:11434.
>>> Install complete. Run "ollama" from the command line.
成功するとollamaの実行可能ファイルが/usr/local/binにインストールされ、 IPアドレスはlocalhost(127.0.0.1)で使用ポートを11434として起動されます。
これでLinuxのインストールは完了です。
コンソールにollamaと打ち込んでEnterを押すと次のようにコマンドのヘルプ画面が表示されます。
kamo@kamo:~$ ollama
Usage:
ollama [flags]
ollama [command]
Available Commands:
serve Start ollama
create Create a model from a Modelfile
show Show information for a model
run Run a model
pull Pull a model from a registry
push Push a model to a registry
list List models
ps List running models
cp Copy a model
rm Remove a model
help Help about any command
Flags:
-h, --help help for ollama
-v, --version Show version information
Use "ollama [command] --help" for more information about a command.
後は次節で紹介するAI(LLM)モデルのダウンロードを実施することでAIと会話ができます。
LLMモデルファイルをダウンロードしてAIと会話してみる
前節でインストールしたOllamaを起動して、AIと会話をしてみましょう。
AIと会話を始めるには、AI(LLM)モデルファイルをダウンロードしてOllamaを実行する必要があります。 この節では基本的なLLMモデルについて説明し、その後にAIを実行するための手順を記載します。
LLMモデルファイル
AIを起動するには、LLMモデルファイルをダウンロードする必要があります。 Ollamaの公式サイトで配布されているLLMをいくつかピックアップすると以下の通りです。
| LLMモデル名 | 説明 |
|---|---|
| Gemma |
Googleがオープンソースで公開しているLLMです。
GPUが搭載されていないノートパソコンなどでも比較的高速に実行することができます。
2024年8月現在の最新バージョンはGemma2です。
Gemma2のモデルファイル名gemma2:2b、gemma2、gemma2:27b |
| llama |
Meta(旧Facebook)が開発したオープンソースのLLMです。
2024年8月現在の最新バージョンはllama3.1です。
llama3.1のモデルファイル名llama3.1 |
| phi |
Microsoftが開発したオープンソースのLLMです。
軽量でコンパクトなLLMです。2024年8月現在の最新バージョンはphi3です。
phi3のモデルファイル名phi3:mini、phi3:medium、phi3:medium-128k |
| Mistral |
Mistral AIが開発したLLMです。2024年8月現在の最新バージョンは0.3です。
mistralのモデルファイル名mistral |
その他のLLMについては公式サイトを確認してください。 なお、自分で調整(ファインチューニング)したカスタムLLMモデルも実行することができます。
今回は、あまりスペックが良くないPC上でも動作し、それなりに賢いLLMモデルのGemma2(gemma2:2b)を使って 会話をしてみたいと思います。
OllamaによるAI(LLM)実行手順
手順1:コンソールの起動
Windowsをお使いの方は検索欄に「cmd」と入力してコマンドプロンプトを起動してコンソール画面を表示してください。
Linuxをお使いの方はterminal(端末)を起動してコンソール画面を表示してください。
手順2:ollama runコマンドの実行
コンソール上で次のrunコマンドを実行することで、指定のLLMモデルファイルを読み込んでOllamaを起動します。
このとき、指定したLLMモデルファイルがまだダウンロードされていない場合は、実行前にダウンロードします。
(この例ではGemma2(gemma2:2b)を起動しています。)
ollama run gemma2:2b
手順3:会話をしてみる
モデルのダウンロードが完了してLLMが実行されると、次に示す画面のようにOllamaはユーザー入力を待ち受けます。
>>> Send a message? (/? for help
そのため、日本語でも英語でも何でも良いので何かメッセージを書いてEnterを押してみてください。
>>> こんにちは
AIからの返信がコンソールに表示されます。
>>> こんにちは こんにちは! 何かご用ですか?
このように、Ollamaをインストールすれば直ぐにAIを利用することができます。
もし、自分好みのAIにカスタムしたい場合はファインチューニングをする必要があります。
ここら辺は、私の専門外のため言及はしませんが、Google Colabや Hugging Faceなどの機械学習系プラットフォームサービスでファインチューニングができるようです。
興味がありましたら、一度そちらのサービスの使い方を勉強してAIの調整にトライしてみてください。
AIと日本語での会話について
ここで紹介したLLMモデルは素の状態だと英語に特化していますので、日本語で会話をしたい場合は日本語会話用にファインチューニングされたLLMモデルを利用するのがベストです。
AIチャットインタフェース(WebUI)の作成
コンソール上でのAIとの会話は少々殺風景に感じます。
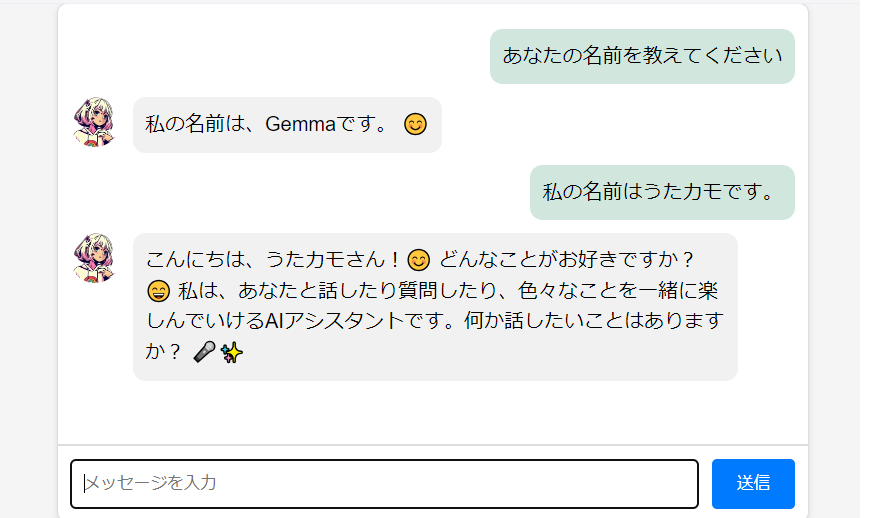
そこで、私はAIと会話するためのLINE風チャットインタフェース(WebUI)を作成しました。
今回作成したAIチャットインタフェースは以下のものです。
(ここではAIモデルのGemma2(gemma2:2b)を使用しているので自身の名前をGemmaと名乗っています。)
この節では、AIとインタラクティブに会話するためのチャットインタフェースを開発する際に最低限必要な知識のみを 抜粋して説明します。
具体的にはチャットをするための送信データの構造について説明し、 後は実際のチャットインタフェース本体のファイル(HTML、CSS、JavaScript)を読者各自で見てもらう方針で紹介します。
※ちなみに、チャットインタフェース(WebUI)はフレームワークなしで作成しています。
一問一答形式で返答させたい場合
POSTデータとして次のJSONを送信すると、一問一答形式で返事してくれます。
curl -X POST http://localhost:11434/api/generate -d '{ <--- 自機にOllamaをインストールしてる場合はlocalhost
"model": "<モデル名 例: gemma2:2b>", <--- ここに会話したいAIのLLMモデルファイル名を指定する
"prompt":"<メッセージ 例: こんにちは>"
}'
OllamaはAIサーバーを11434ポートで起動します。そのため、ユーザーが送信したチャットメッセージがOllamaに届くように OllamaのホストPCのIPアドレス(上記の例ではlocalhost(127.0.0.1))と11434ポートの指定が必要です。
この例では、OllamaをインストールしたPCの中でAIとユーザーのチャット送受信を自己完結しますので、 IPアドレス指定に関してはlocalhost(127.0.0.1)を指定しています。
チャット形式でやりとりしたい場合
POSTデータとして次のJSONを送信すると、チャット形式で応答します。
curl -X POST http://localhost:11434/api/chat -d '{
"model": "<モデル名 例: gemma2:2b>",
"messages": [
{ "role": "user", "content": "<メッセージ 例: こんにちは>" }
]
}'
過去の会話を踏まえた上でチャットをしたい場合は、次のように以前のやり取りを履歴データとして付加して新しいチャットメッセージを送信します。 (role:userはユーザーが入力したチャット、 role:assistantはAIのチャット履歴です。)
curl -X POST http://localhost:11434/api/chat -d '{
"model": "gemma2:2b",
"messages": [
{ "role": "user", "content": "こんにちは" },
{ "role": "assistant", "content": "こんにちは!"},
{ "role": "user", "content": "私の名前はうたカモです。よろしくお願いします。"},
{ "role": "assistant", "content": "うたカモさんですね。よろしくお願いします。"},
{ "role": "user", "content": "今日はLinuxについて教えてください。"}
]
}'
上記で紹介した方法で実際に動作確認をしてみる
Gemma2(gemma2:2b)に対して「こんにちは」とメッセージ(prompt)を送信する例は以下の通りです。 (ここでは一問一答形式でメッセージを送信してみます。)
### Windowsのコマンドプロンプト上でcurlコマンドを実行する例 ### C:¥Users¥xxxx> curl -X POST "http://localhost:11434/api/generate" -H "Content-Type: application/json" -d "{\"model\":\"gemma2:2b\",\"prompt\":\"こんにちは\"}" ### OR ### C:¥Users¥xxxx> curl.exe -X POST "http://localhost:11434/api/generate" -H "Content-Type: application/json" -d "{\"model\":\"gemma2:2b\",\"prompt\":\"こんにちは\"}" ### WindowsのPowerShell上でcurlコマンドを実行する例 ### C:¥Users¥xxxx> $response = Invoke-WebRequest -Uri "http://localhost:11434/api/generate" ` -Method POST ` -Headers @{"Content-Type"="application/json"} ` -Body '{"model": "gemma2:2b", "prompt": "こんにちは"}' C:¥Users¥xxxx> $response.RawContent
### Linuxのterminal上でcurlコマンドを実行する例 ### kamo@kamo:~$ curl -X POST http://localhost:11434/api/generate -d '{ "model": "gemma2:2b", "prompt":"こんにちは" }'
上記のcurlコマンドでPOSTデータをOllamaに送信するとその応答が返ってきます。
{"model":"gemma2:2b","created_at":"2024-08-09T12:24:40.115387Z","response":"こんにちは","done":false}
{"model":"gemma2:2b","created_at":"2024-08-09T12:24:40.2575106Z","response":"!","done":false}
{"model":"gemma2:2b","created_at":"2024-08-09T12:24:40.370512Z","response":" 😊","done":false}
{"model":"gemma2:2b","created_at":"2024-08-09T12:24:40.4801315Z","response":" ","done":false}
{"model":"gemma2:2b","created_at":"2024-08-09T12:24:40.5972409Z","response":"\n\n","done":false}
{"model":"gemma2:2b","created_at":"2024-08-09T12:24:40.708938Z","response":"何か","done":false}
{"model":"gemma2:2b","created_at":"2024-08-09T12:24:40.8263056Z","response":"お手","done":false}
{"model":"gemma2:2b","created_at":"2024-08-09T12:24:40.942445Z","response":"伝","done":false}
{"model":"gemma2:2b","created_at":"2024-08-09T12:24:41.0560709Z","response":"い","done":false}
{"model":"gemma2:2b","created_at":"2024-08-09T12:24:41.2275955Z","response":"できる","done":false}
{"model":"gemma2:2b","created_at":"2024-08-09T12:24:41.3435589Z","response":"ことは","done":false}
{"model":"gemma2:2b","created_at":"2024-08-09T12:24:41.4520451Z","response":"ありますか","done":false}
{"model":"gemma2:2b","created_at":"2024-08-09T12:24:41.5607527Z","response":"?","done":false}
{"model":"gemma2:2b","created_at":"2024-08-09T12:24:41.6754887Z","response":" ","done":false}
{"model":"gemma2:2b","created_at":"2024-08-09T12:24:41.7868181Z","response":"\n","done":false}
{"model":"gemma2:2b","created_at":"2024-08-09T12:24:41.9019212Z","response":"","done":true,"done_reason":"stop","context":[106,1645,108,32789,107,108,106,2516,108,32789,235482,44416,235248,109,50837,120387,237210,235395,15417,26548,188831,235544,235248,108],"total_duration":8273798500,"load_duration":5759006000,"prompt_eval_count":10,"prompt_eval_duration":719644000,"eval_count":16,"eval_duration":1786462000}
レスポンスの結果から、応答文字列が随時返ってくることが分かります。
AIチャットインタフェース(WebUI)のダウンロードと起動
前提条件
その1
実行したいLLMモデルを予めOllama上にダウンロードしていること。コンソールを開いて
ollama run gemma2:2bやollama pull gemma2:2b
でLLMモデル(この例ではgemma2:2b)をダウンロードできます。
その2
Webブラウザ上のUI画面からAIとチャットをするためには、OllamaにCORS設定を適用する必要があります。
説明が前後しますが、次節の宅内ネットワーク(LAN)内で家族もAIを利用できるようにする方法を参照してOllamaの設定を追加してください。
上記のチャットメッセージの送受信仕様を基に作成したチャットインタフェースを動かしてみます。 まず、次のリンクからUIファイル一式が入ったZIPファイルをダウンロードして展開します。
AIチャットインタフェース(WebUI)のダウンロード
展開されたフォルダの中にindex.htmlという名前のHTMLファイルがあるのでGoogle ChromeやEdge、Firefox などのWebブラウザーの画面にドラッグ&ドロップします。
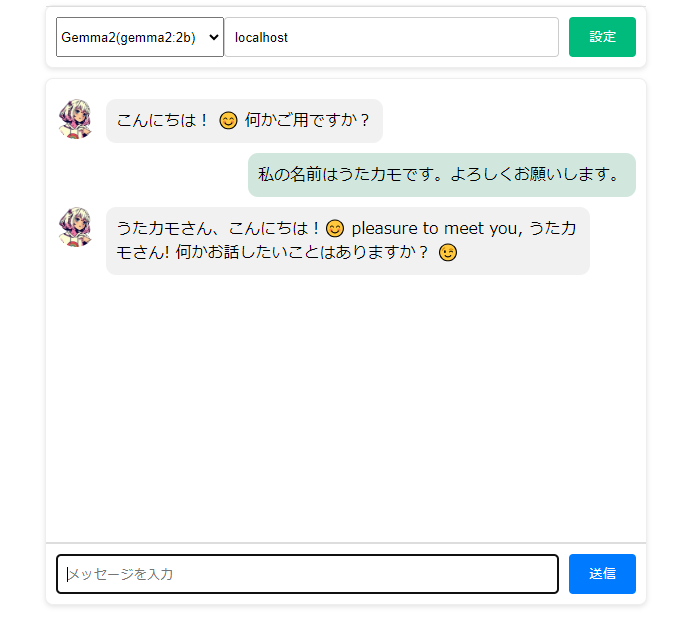
次のAIチャット画面が表示されたら、LLMモデルの選択とIPアドレス(Ollamaが起動しているPC上でUIを利用する場合は「localhost」) を指定します。
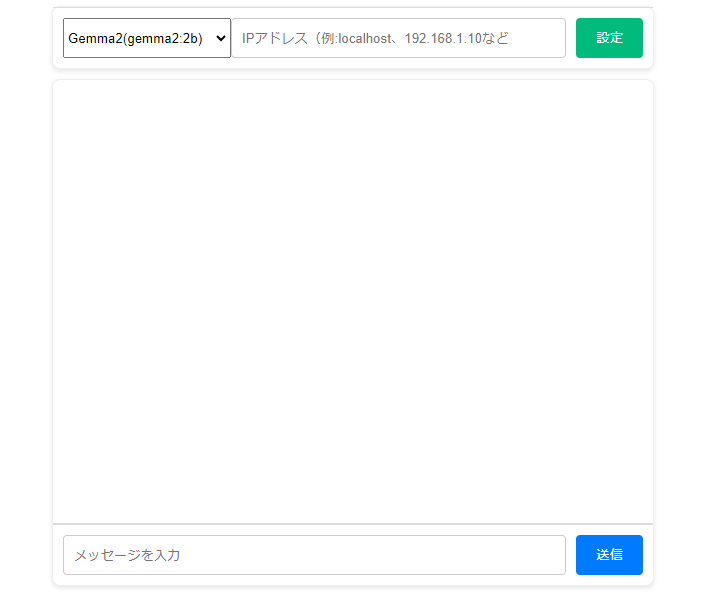
LLMモデルの選択とIPアドレス指定をしたら「設定」ボタンを押します。設定内容が正しければ、AIから応答が返って来ます。
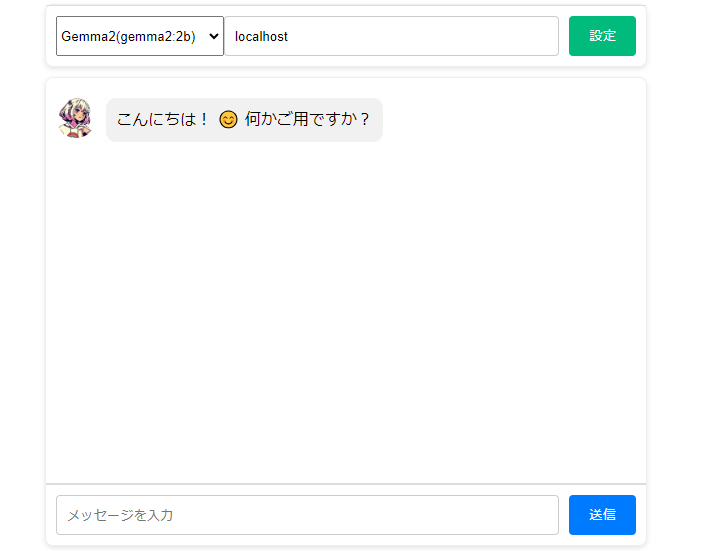
後は画面下部のメッセージボックスに自由にチャットメッセージを入力して「送信」ボタンを押すと会話が開始されます。
宅内ネットワーク(LAN)内で家族もAIを利用できるようにする方法
ここで取り上げる設定内容は、セキュリティが十分確保されたLocal Area Network(LAN)内で利用する ことを前提にしています。 ネットワークを利用したOllamaのAIサーバーの利用範囲としてWide Area Network(WAN)を希望している場合、 ここで紹介した内容で設定するのは危険です。通信プロトコルもHTTPSに変更した方がいいでしょう。 予めご了承お願いします。
ここでは宅内ネットワーク(LAN)に所属するスマホやPCがOllamaを運用しているPCとAIチャットできるようになる 設定を紹介します。
具体的には以下2つのOllamaパラメーターを設定することで実現します。
OLLAMA_HOST
Ollamaが利用するIPアドレスを設定するためのパラメーターです。 デフォルトではOLLAMA_HOSTは定義されていないため、OllamaはローカルIP(127.0.0.1)を利用するようになっています。 そのため、Ollamaは同じホスト(127.0.0.1)内から送信されてきたユーザーリクエストのみを処理し、応答を返します。 OLLAMA_HOST=0.0.0.0と設定すると、OllamaはホストPCが使用するNICのIPアドレスを利用対象IPアドレスとして設定します。 もし、OllamaのホストPCが特定のLAN(例:192.168.3.x)に所属しており、IPアドレスとして192.168.3.7を割当てられていた場合、 同じLAN内に所属する端末は192.168.3.7宛てにリクエストを送信すればOllamaはそのリクエストを処理して応答を返します。
OLLAMA_ORIGINS
OllamaにアクセスできるドメインやIPアドレスを設定するパラメーターです(CORS設定と言います)。 これはアクセス元が許可されたものであるかを確認するために利用されます。 例えば、私のサイト(https://utakamo.com)からのユーザーリクエストのみを受け付ける場合は OLLAMA_ORIGINS=https://utakamo.comと設定します。今回はLAN内での動作確認を目的として、 全てのアクセス元を許可する設定であるOLLAMA_ORIGINS=*を適用します。
それでは、以下に設定例をWindowsとLinux別で掲載します。
Windowsの環境変数設定
Windowsのメインウィンドウの左下にある検索欄で「システム環境変数の編集」と入力&Enterを押して次の画面を表示します。
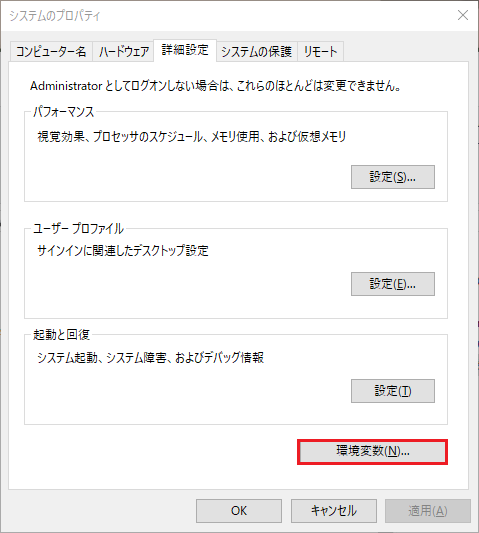
ユーザー変数一覧下の「新規」ボタンを押します。
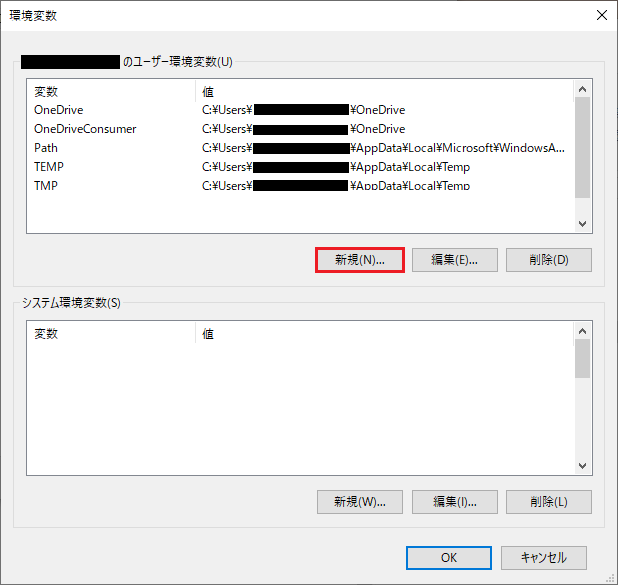
変数名に「OLLAMA_HOST」、変数値に「0.0.0.0」と入力して「OK」ボタンを押します。
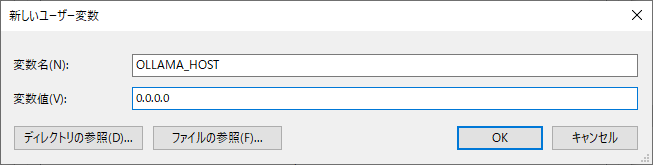
同じ要領で「新規」ボタンをもう一度押し、今度は変数名に「OLLAMA_ORIGINS」、変数値に「*」と入力して「OK」ボタンを押します。
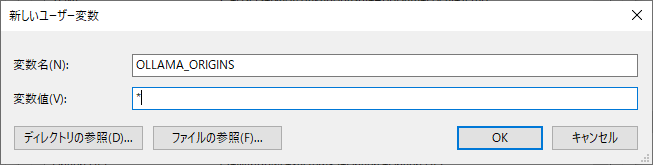
設定が完了すると以下のようにユーザー変数一覧に「OLLAMA_HOST」と「OLLAMA_ORIGINS」が存在するはずです。
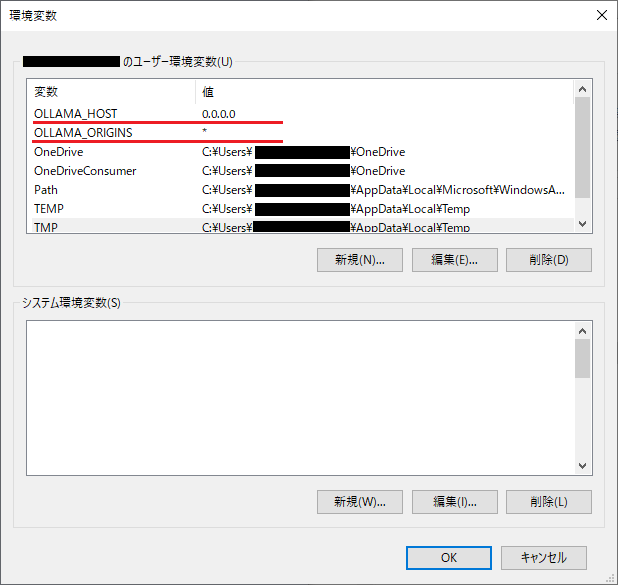
確認が終わったら一度Windowsを再起動しましょう。
これでWindowsの環境変数設定は完了です。
Linuxのollamaパラメーター設定
terminal(端末)を起動してコンソール画面を表示したら、そこに次のコマンドを打ち込みOllama設定の編集を開始します。
kamo@kamo:~$ sudo systemctl edit ollama.service
設定内容の末尾に次のパラメーター記述を追加して保存します。
[Service]
Environment="OLLAMA_HOST=0.0.0.0"
Environment="OLLAMA_ORIGINS=*"
設定保存時の注意点
sudo systemctl edit ollama.serviceは/etc/systemd/system/ollama.serviceの 上書き(オーバーライド)用ファイルを/etc/systemd/system/ollama.service.d/直下に作成します。
大半のLinux OSのデフォルト設定では、このとき使用するデフォルトのエディタツールはnanoなので、 編集内容はCTRL + xで保存&エディタ終了できます。
ただし、このときにsystemctlによって与えられた上書き用ファイル名が保存できない形式の場合があります。 そのときは保存時のファイル名確認時にファイル名を/etc/systemd/system/ollama.service.d/override.conf にでも変更してください。(これをやっても上手く行かないと思ったら設定ファイル本体の/etc/systemd/system/ollama.service にOLLAMA_HOSTとOLLAMA_ORIGINSの設定を直書きしてください)
ちなみに、nanoエディタの使い方はこちら。
最後に、次のコマンドでOllamaを再起動します。
kamo@kamo:~$ sudo systemctl daemon-reload kamo@kamo:~$ sudo systemctl restart ollama
これでLinuxのOllamaパラメーター設定は完了です。
別のホストからOllamaが動作しているPCにメッセージ(チャット)を送信してみる
再起動後はOllamaが外部ホストからのリクエストを受け付け、都度返答を返してくれるようになっています。 LAN内の外部ホストであれば、Ollamaが動作しているPCのIPアドレスとポート番号11434の組でメッセージを届けることができます。
もし、Ollamaが動作しているPCがLAN内の192.168.3.7であれば、同じLANに所属する別のPCからは次のcurlコマンドを実行することで メッセージを送信することができます。
### Windowsのコマンドプロンプト上でcurlコマンドを実行する例 ### C:¥Users¥xxxx> curl -X POST "http://192.168.3.7:11434/api/generate" -H "Content-Type: application/json" -d "{\"model\":\"gemma2:2b\",\"prompt\":\"こんにちは\"}" ### OR ### C:¥Users¥xxxx> curl.exe -X POST "http://192.168.3.7:11434/api/generate" -H "Content-Type: application/json" -d "{\"model\":\"gemma2:2b\",\"prompt\":\"こんにちは\"}" ### WindowsのPowerShell上でcurlコマンドを実行する例 ### C:¥Users¥xxxx> $response = Invoke-WebRequest -Uri "http://192.168.3.7:11434/api/generate" ` -Method POST ` -Headers @{"Content-Type"="application/json"} ` -Body '{"model": "gemma2:2b", "prompt": "こんにちは"}' C:¥Users¥xxxx> $response.RawContent
### Linuxのterminal上でcurlコマンドを実行する例 ### kamo@kamo:~$ curl -X POST http://192.168.3.7:11434/api/generate -d '{ "model": "gemma2:2b", "prompt":"こんにちは" }'
また、今回作成したチャットインタフェース(WebUI)からもメッセージのやり取りができるようになります。
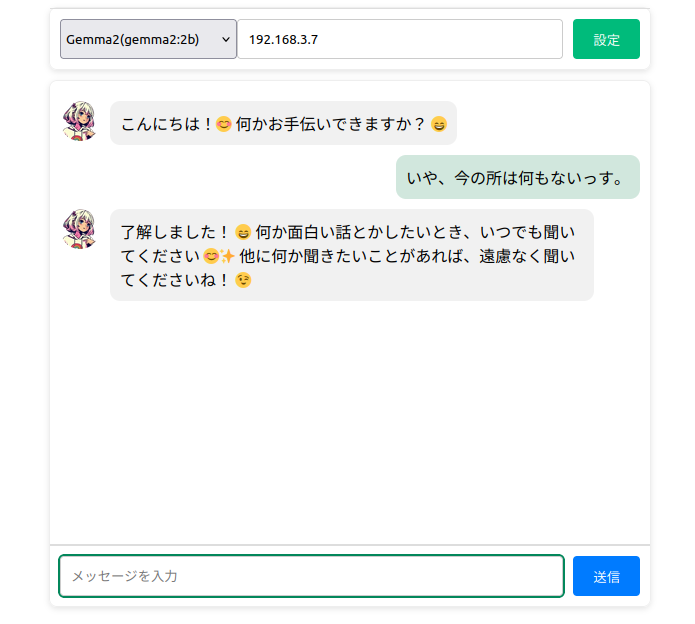
おわりに
今回はOllamaによって手持ちPCにAIを導入する方法を紹介しました。
Ollamaを利用すれば簡単にローカル環境でスタンドアロンのAIを導入できることを実感していただけたと思います。
この記事では配布されている素のLLMモデルを利用しているため、AIに対してキャラクタ(個性)を 感じることはほぼ無いと思います。
しかし、ファインチューニングなどを通してAIに個性を持たせた上でイラストなどを使って擬人化したりすると エンタメ性のあるAIサービスなどが作れると思います。
今回はAI擬人化の第一歩として、キャラクタのイラストをAIに見立ててLINE風のUIでチャットをしてみたりもしましたが、 これだけでもエンタメ感のある雰囲気が出ます(実際どうでしょうか?)。
エンタメに限らず、特定作業に特化するようにファインチューニングすれば仕事を手伝ってくれる相棒にもなってくれるでしょう。
何はともあれ、今回の内容を切っ掛けにさまざまなAI技術に触れてみてください。
余談その1
この記事を作成したきっかけは、このサイト(https://utakamo.com)に「AIによる記事の要約機能」と「質問を投げかけたら関連性が高い 自サイトのリンクを案内する機能」を実装するためにAI(LLM)について調べていたからです。
取り敢えず、目的通りに機能するものは作れるだろうという結論に至りましたが、ハードウェアリソースの問題に直面しました。
格安レンタルサーバーでこのサイトを運用してますので「とにかくメモリが足らない、GPUが使えない」などの理由で AIサービスの実装は保留状態です(多人数による集中的なリクエストを裁き切れません)。
自宅のPCをWAN上に公開して、そのPC上でollamaなどのAIサーバーを起動させようと思いましたが、如何せん私が持っている PCは超低スペックなので目的を達成しません。
なので、AIサービス実装の代わりにこの記事を書くことにしました。
結局、多人数にAIサービスを提供しようとなるとクラウドベースのChatGptやMicrosoft Copilotのような賢いAIサービスを上手く使う 方が理にかなっているのかなと思います。トチ狂ってAIサーバー用のPCを自前用意するかもしれませんが。
今回記事で使用したイラストについて
Microsoft Copilotに「utakamo.comというサイトをイメージしたイラストをポップなデザインで描いて」という謎プロンプトを 投げたら今回の女の子のイラストを生成してくれました。Copilot(というかDall-E2)がせっかく作ってくれたので この記事で使用することにしました。
ちなみに元のイラストがこれです。(このイラストを元にremove.bgとかGimpを使って加工し、タイトルイラストとチャット用アイコンを作りました。)

余談その2(2025年1月13日追記)
リスキリングの一貫で学習したAI知識の成果をこの技術記事一本で終わらせるのはもったいないと思いました。
そこで、私は主にルーターなどの組み込み機器に利用されるLinuxディストリビューションのOpenWrtにAIとの連携機能を組み込むことを思いつきました。 そして開発したアプリケーションがOpenWrt専用AIアシスタントツールのOasisです。※対応するAIサービスはOllamaとOpenAIです。
OasisはOpenWrtデバイスにAIとの対話機能を付加し、専用のチャットインタフェースをユーザーに提供します。 これにより、ユーザーはOpenWrtデバイスを介してAIに対してメッセージを送信することが可能になります。
ユーザーがAIにメッセージを送信し、その応答がOpenWrtデバイスに到達すると、 OasisはAIの応答メッセージの中にOpenWrtの設定変更に関する提案が含まれているか分析します。
設定変更の提案が含まれている場合、OasisはユーザーにAIの提案に従ってOpenWrtの設定を変更するか 問い合わせます。ユーザーが内容を確認し、承認すれば設定は適用されます。
以下ではWebUI(LuCI)とコンソールのそれぞれからOasisを利用したときの概要を紹介します。
[WebUI版Oasis(luci-app-oasis)]
OasisのWebUI画面上での操作例です。AIがユーザーに代わってOpenWrtデバイスの詳細な設定変更を代行します。
ユーザーは日本語や英語などの自然言語でAIにOpenWrtの設定をお願いするだけで済みます。
[CUI版Oasis(/usr/bin/oasis)]
OasisのCUI画面上での操作例です。WebUI版Oasisのコアソフトウェアにもなっており、AIとの対話制御などは全てのこのソフトウェアがしています。
OasisにはAIにネットワーク・Wi-Fi設定の変更をさせる機能を組み込んでいます。 そのため、Oasisはユーザーに提案内容の通知し、設定の確認と適用の最終判断を促します。
しかし、潜在的にはユーザーの確認を一切介さずにAIが自立的に組み込み機器を操作することも可能です。
つまり、私はこのOasisに「AIに組み込み機器を操作させる仕組み」を実装しました。 (現在のOasisには制限を掛けて、AIにOSコマンドの実行をさせないようにしています。)
今後、Oasisに関する使い方と仕組みについて記事を書きたいと思いますので興味がありましたら読んでみてください。
【個人開発】OpenWrt専用AIアシスタントツール Oasisの導入と使い方
参考文献
- Ollama Model Library: https://ollama.com/library
- Ollama GitHub API Document: https://github.com/ollama/ollama/blob/main/docs/api.md#api
- Ollama GitHub REST API: https://github.com/ollama/ollama?tab=readme-ov-file#rest-api
- Ollama GitHub Setting environment variables on Windows: https://github.com/ollama/ollama/blob/main/docs/faq.md#setting-environment-variables-on-windows
- Ollama GitHub Setting environment variables on Linux: https://github.com/ollama/ollama/blob/main/docs/faq.md#setting-environment-variables-on-linux